Difference between revisions of "Plugins"
(→Network Generation) |
|||
| (103 intermediate revisions by 8 users not shown) | |||
| Line 1: | Line 1: | ||
| − | + | __NOEDITSECTION__ | |
| + | The geWorkbench platform employs a component repository infrastructure to manage a large collection of pluggable components that can be used to customize the application's graphical user interface. This (ever growing) list of plug-in components covers a wide range of fucntionality for a number of different genomic data modalities. | ||
| − | The | + | The Status of the pluggable components below is defined as: |
| − | |||
{|style="border: 1px solid lightGray" | {|style="border: 1px solid lightGray" | ||
| − | ! | + | !Status||Comment |
|- | |- | ||
|- | |- | ||
| − | | | + | |width="120"|(a) Released||This plugin is part of the latest geWorkbench version. |
|- | |- | ||
| + | |width="120"|(b) Development||This plugin is currently actively being developed. | ||
|- | |- | ||
| + | |- | ||
| + | |} | ||
| + | |||
| + | |||
| + | |||
| + | __TOC__ | ||
| + | |||
| + | |||
| + | ==Analysis== | ||
| − | | | + | {|class = "wikitable" style="border: 1px solid lightGray" |
| + | !Plugin||Status||Description | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|ANOVA||Released||Analysis of Variance - detection of significant differences in expression between more than two groups. ([[media:T_ANOVA_ColorMosaic.png|Screenshot]]) | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|Evidence Integration||Development||A sequence and structure-based approach for functional annotation and protein-protein interaction analysis. | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|GSEA||Released||The Gene Set Enrichment Analysis determines whether an a priori defined set of genes shows statistically significant differences between two phenotypes. | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|Hierarchical Clustering||Released||Clustering of markers and microarrays into hierarchical binary trees. The resulting structures can be visualized in the Dendrogram plugin. ([[media:T_HC_Dendrogram_display.png|Screenshot]]) | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|KNN||Released||k-Nearest Neighbors analysis (a GenePattern component). | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|MatrixReduce||Released||Transcription Factor binding motifs. ([[media:T_MatrixREDUCE_PSAM_view.png|Screenshot]]) | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|MEDUSA||Development||The Motif Element Detection Using Sequence Agglomeration is an integrative method for learning motif models of transcription factor binding sites by incorporating promoter sequence and gene expression data (Leslie Lab, MSKCC). | ||
| + | |- | ||
|- | |- | ||
| + | |width="150"|MRA||Released||Master Regulator Analysis combines regulatory information from interaction networks with differential expression analysis. ([[media:MRA_viewer_full.png|Screenshot]]) | ||
|- | |- | ||
| − | | | + | |- |
| + | |width="150"|PCA||Released||Principal Component Analysis (a GenePattern component). | ||
|- | |- | ||
|- | |- | ||
| − | | | + | |width="150"|SOM||Released||Clustering of markers using Self Organizing Maps. The resulting clusters can be visualized in the SOM Clusters Viewer plugin. ([[media:T_SOM_result.png|Screenshot]]) |
| + | |- | ||
| + | |- | ||
| + | |width="150"|SVM 3.0||Released||The Support Vector Machine is a supervised classification method that computes a maximal separating hyperplane between the expression vectors of different classes or phenotypes (a GenePattern component). | ||
| + | |- | ||
| + | |- | ||
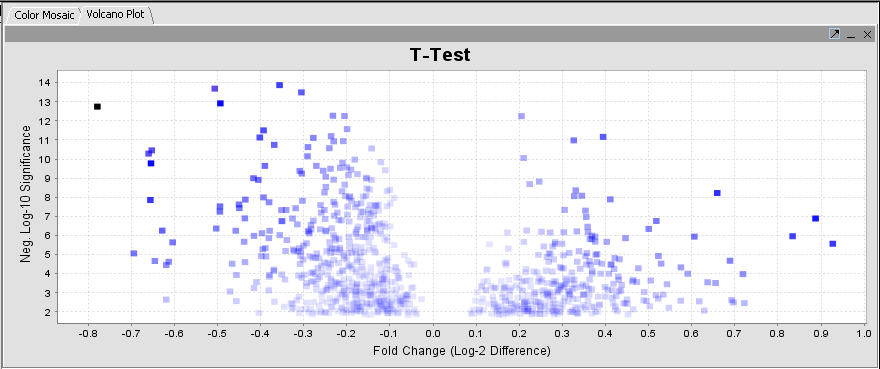
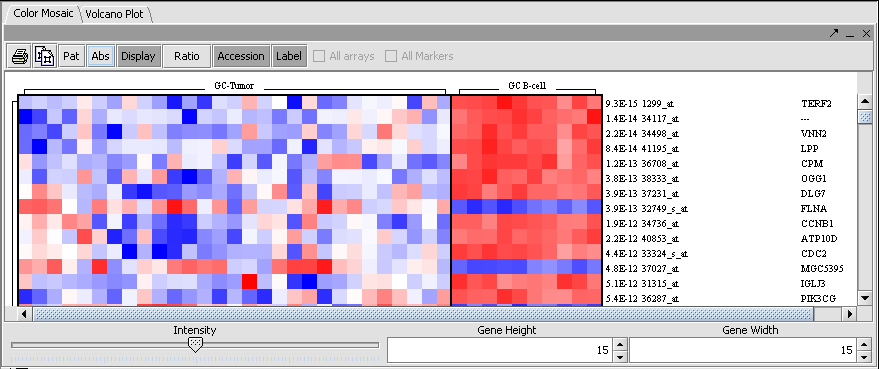
| + | |width="150"|T-Test||Released||Identification of markers with statistically significant differential expression between sets of microarrays. ([[media:T_t-test_volcano_BCELL_webm_qldm.png|Screenshot Plot]], [[media:T_t-test_colormosaic_BCELL_webm_qldm.png|Screenshot Mosaic]]) | ||
| + | |- | ||
|- | |- | ||
| + | |width="150"|Weighted Voting||Released||Weighted Voting Analysis (a GenePattern component). | ||
|- | |- | ||
| + | |- | ||
| + | |} | ||
| + | |||
| + | |||
| + | ==Annotation== | ||
| − | |Microarray | + | {|class = "wikitable" style="border: 1px solid lightGray" |
| − | |- | + | !Plugin||Status||Description |
| + | |- | ||
| + | |- | ||
| + | |width="150"|caScript||Development||An Editor. | ||
| + | |- | ||
| + | |-|width="150"|Dataset Annotation||Released||Free text format box used to annotate data, images and results. Such annotations persist application invocations and can be used as an online notebook. | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|Dataset History||Released||Log of data transformations induced by data-modifying operations. | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|Experiment Information||Released||Microarray machine parameters used in an experiment run. If available, high-level experiment information (e.g., purpose of of experiment) are also displayed. | ||
| + | |- | ||
| + | |- | ||
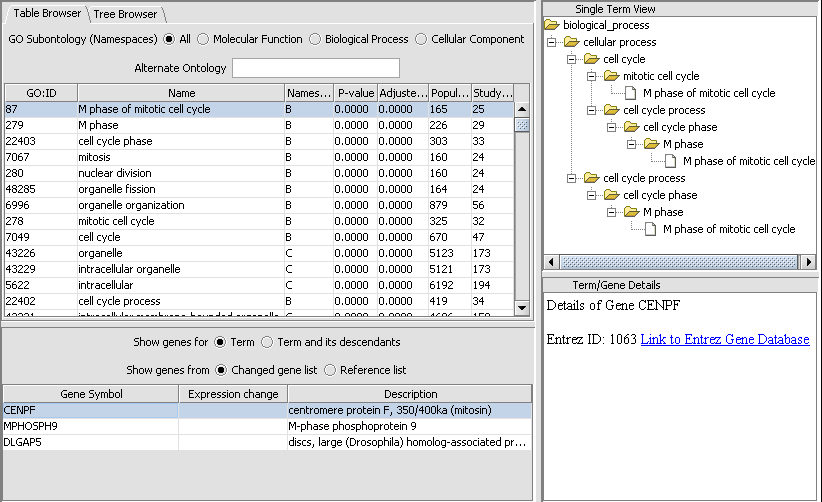
| + | |width="150"|Gene Ontology Enrichment||Released||Enrichment analysis of selected groups of genes against Gene Ontology (http://www.geneontology.org) annotations. ([[media:T_GO_Terms_TableBrowser_Gene_Detail.png|Screenshot]]) | ||
| + | |- | ||
| + | |- | ||
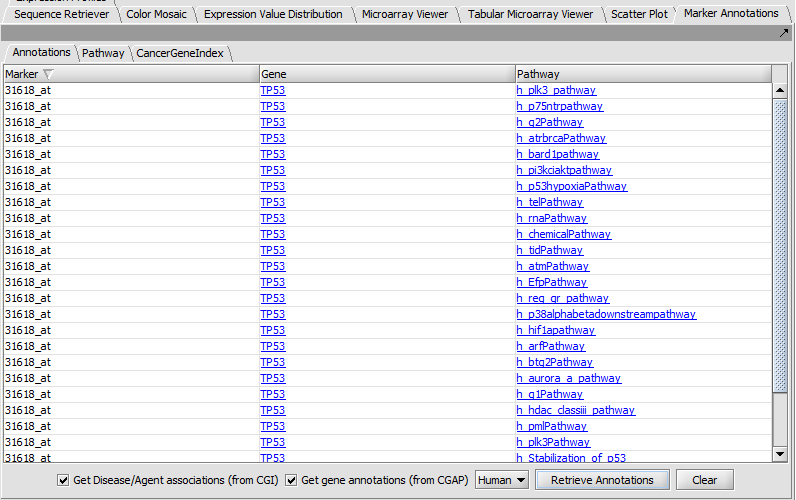
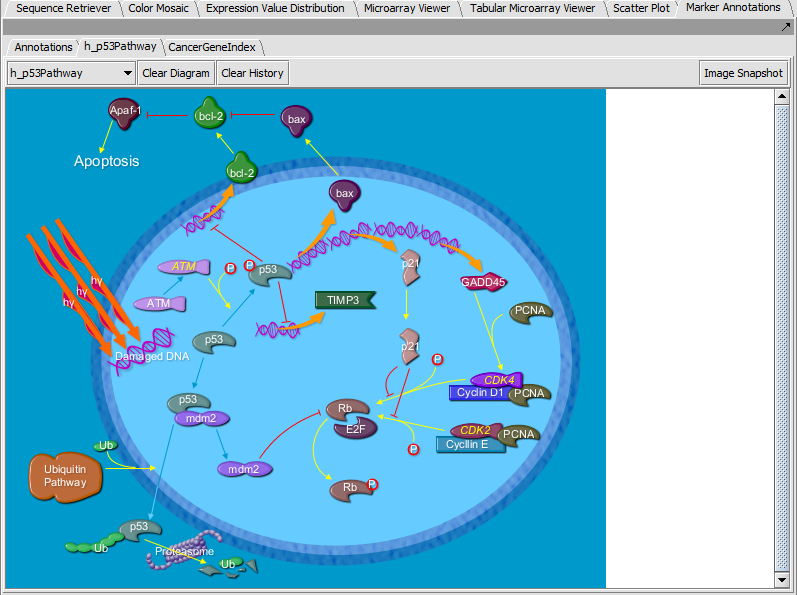
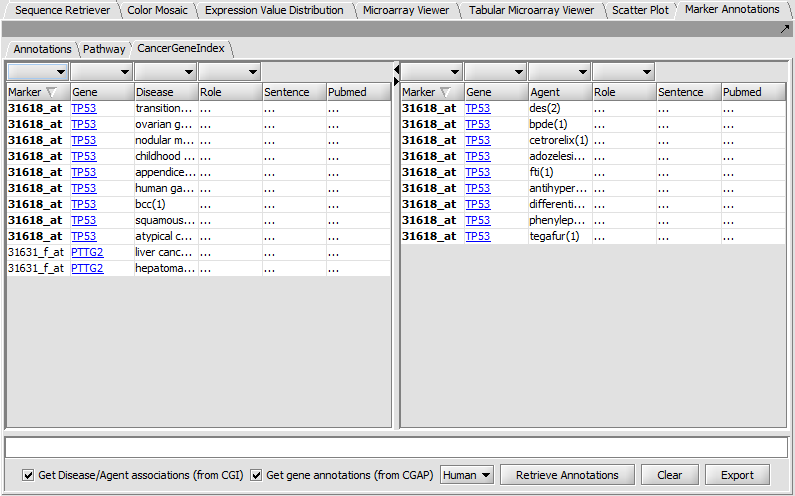
| + | |width="150"|Marker Annotations||Released||Retrieval of gene and pathway information for markers on a microarray (caBIO Pathways/Cancer Gene Index); it includes visualization of BioCarta pathway diagrams. ([[media:GeWB_Marker_Annotations.png|Screenshot Table]], [[media:GeWB_Marker_Annotations_Pathway.png|Screenshot BioCarta]], [[media:GeWB_Marker_Annotations_CGI.png|Screenshot CGI]]) | ||
| + | |- | ||
|- | |- | ||
| + | |} | ||
| + | |||
| + | |||
| + | ==Data Filtering== | ||
| − | | | + | {|class = "wikitable" style="border: 1px solid lightGray" |
| − | |- | + | !Plugin||Status||Description |
| + | |- | ||
| + | |- | ||
| + | |width="150"|Affy Detection Call Filter||Released||Filtering of measurements based on the value of their "detection call" attribute ''(Affymetrix data only)'' . | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|Deviation Filter||Released||Filtering of markers with low dynamic range. | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|Expression Threshold Filter||Released||Elimination of measurements that fall outside a range of explression values. | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|2-channel Threshold Filter||Released||Same as "Expression Threshold" filter but different threshold ranges can be specified for each channel ''(GenePix data only)''. | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|Genepix Flag Filter||Released||Filtering of measurements based on the value of their "Flags" attribute ''(GenePix data only)''. | ||
| + | |- | ||
|- | |- | ||
| − | + | |width="150"|Missing Value Filter||Released||Discards all markers that have missing measurements in more than a user specified number N of microarrays. | |
| − | | | ||
| − | | | ||
|- | |- | ||
| − | |||
| − | |||
|- | |- | ||
|} | |} | ||
| + | |||
==Data Management== | ==Data Management== | ||
| − | {|style="border: 1px solid lightGray" | + | |
| − | !Plugin|| | + | {|class = "wikitable" style="border: 1px solid lightGray" |
| + | !Plugin||Status||Description | ||
|- | |- | ||
|- | |- | ||
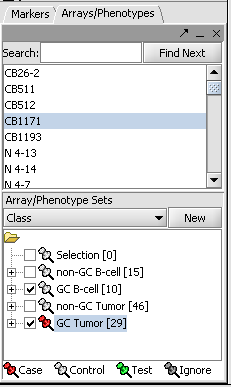
| − | | | + | |width="150"|Arrays/Phenotypes||Released||Definition of data views consisting of microarray subgroups. The views control the amount of data displayed. ([[media:T_t-test_Arrays_case-set_BCELL_webm_qldm.png|Screenshot]]) |
| + | |- | ||
| + | |- | ||
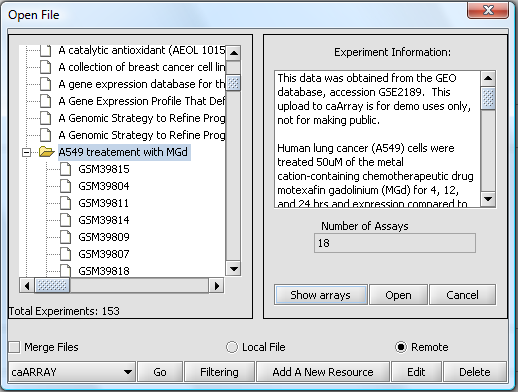
| + | |width="150"|caArray||Released||Search and download of gene expression data from instances of caArray (NCI microarray database product). ([[media:T_caArray_A549_arrays.png|Screenshot]]) | ||
| + | |- | ||
| + | |- | ||
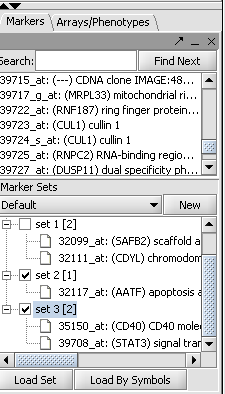
| + | |width="150"|Markers||Released||Definition of data views consisting of marker subgroups. The views control the amount of data displayed. ([[media:Select_marker_sets.png|Screenshot]]) | ||
|- | |- | ||
|- | |- | ||
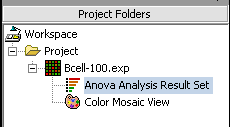
| − | | | + | |width="150"|Project Folders||Released||Manages projects and workspaces of the user. ([[media:T_ANOVA_Saved_Color_Mosaic_View.png|Screenshot]]) |
|- | |- | ||
|- | |- | ||
|} | |} | ||
| − | == | + | |
| − | {|style="border: 1px solid lightGray" | + | ==File Import== |
| − | !Plugin||Description|| | + | |
| + | {|class = "wikitable" style="border: 1px solid lightGray" | ||
| + | !Plugin||Status||Description | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|Affymetrix CEL||Released||Loads Affymetrix probe CELl intensity files ("*.cel"). | ||
| + | |- | ||
|- | |- | ||
| − | | | + | |width="150"|Affymetrix File Matrix||Released|| Loads Affymetrix EXPperiment files ("*.exp"). |
|- | |- | ||
|- | |- | ||
| − | | | + | |width="150"|Affymetrix MAS5/GCOS||Released|| Loads output files from the GeneChip Operating Software formerly known as MAS5 Statistical algorithm (several different file extension). |
|- | |- | ||
|- | |- | ||
| − | | | + | |width="150"|FASTA Format||Released||Loads files that are in FASTA format ("*.fasta" and "*.txt"). |
| − | |||
|- | |- | ||
|- | |- | ||
| − | | | + | |width="150"|Genepix File Format||Released||Loads files in GenePix Result format ("*.gpr"). |
| − | || | ||
|- | |- | ||
|- | |- | ||
| − | | | + | |width="150"|PDB Structure Format||Released||Loads files in the Protein Data Base format ("*.pdb") |
|- | |- | ||
| − | |||
|- | |- | ||
| + | |width="150"|Tab-delimited (RMA Express Format)||Released||Loads tab-delimited files from the Robust Multichip Analysis ("*.txt") | ||
|- | |- | ||
| − | |||
|- | |- | ||
| + | |} | ||
| − | |||
| − | == | + | ==Menu Tools== |
| − | {|style="border: 1px solid lightGray" | + | {|class = "wikitable" style="border: 1px solid lightGray" |
| − | !Plugin||Description|| | + | !Plugin||Status||Description |
| + | |- | ||
| + | |- | ||
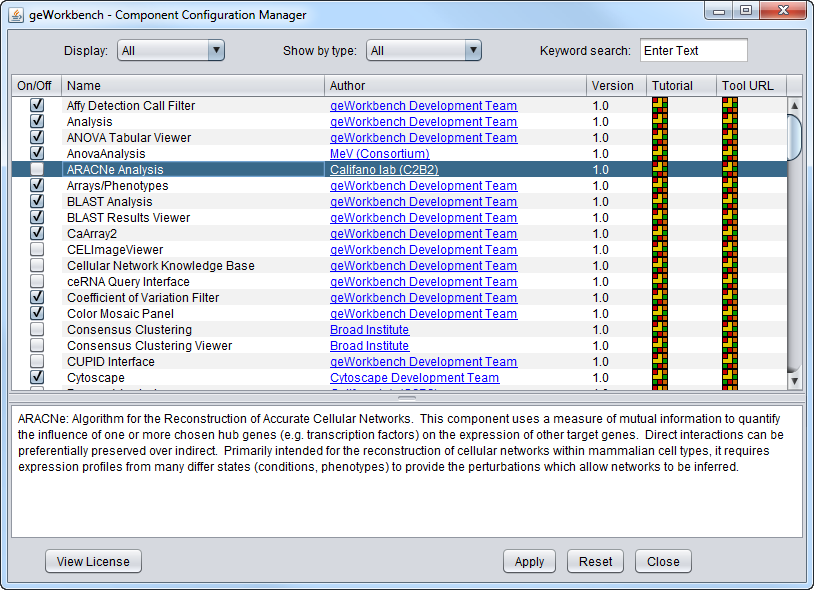
| + | |width="150"|CCM||Released||The Component Configuration Manager allows users to manage plugins dynamically at any given time in the application environment. ([[Media:CCM_Main.png|Screenshot]]) | ||
|- | |- | ||
| − | |||
|- | |- | ||
| + | |width="150"|genSpace||Released||It logs information about the analysis tools used in geWorkbench in order to enable collaboration support for the geWorkbench users. | ||
|- | |- | ||
| − | |||
|- | |- | ||
| + | |width="150"|Online Help||Released||geWorkbench Online Help uses the Java help 2.0 system to provide real-time help on component questions. | ||
|- | |- | ||
| − | |||
|- | |- | ||
| + | |width="150"|Preferences||Released||Allows users to predefine a few basic visual settings and choose a Text Editor. | ||
|- | |- | ||
| − | |||
|- | |- | ||
| + | |width="150"|Version Information||Released||Provides basic information about the currently installed user version of geWorkbench. | ||
|- | |- | ||
| − | |||
|- | |- | ||
| − | | | + | |width="150"|Welcome Screen||Released||Introduction to geWorkbench during the initial opening of the application. |
|- | |- | ||
|- | |- | ||
|} | |} | ||
| + | |||
==Network Generation== | ==Network Generation== | ||
| − | {|style="border: 1px solid lightGray" | + | {|class = "wikitable" style="border: 1px solid lightGray" |
| − | !Plugin||Description|| | + | !Plugin||Status||Description |
| + | |- | ||
| + | |- | ||
| + | |width="150"|ARACNe||Released||The Algorithm for the Reconstruction of Accurate Cellular Networks analyses large amount of microarray data (typically 100-500 microarrays) to reverse engineer underlying gene regulatory networks. ([[media:T_ARACNE_result1.png|Screenshot]]) | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|Cancer GEMS||Development||Interface to the NCI Cancer Genetic Markers of Susceptibility project. | ||
| + | |- | ||
| + | |- | ||
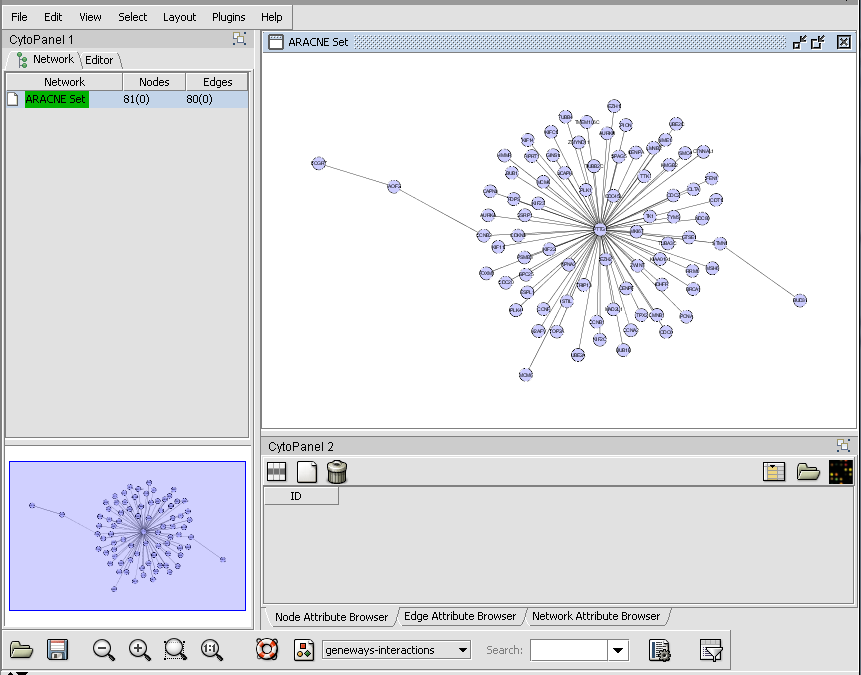
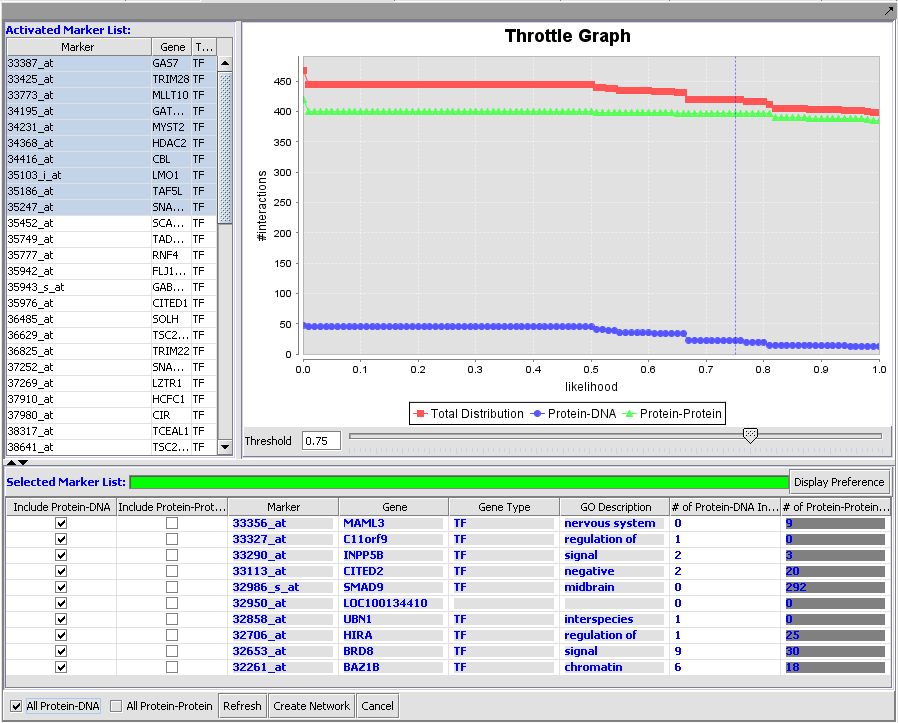
| + | |width="150"|CNKB||Released||The Cellular Networks Knowledge Base queries an in-house repository of locally generated B-cell interaction network data and information from external databases in order to build a network of interactions for selected genes. ([[media:T_CNKB_ProtDNA_confidence75.png|Screenshot Throttle Graph]], [[media:T_CNKB_10at75_Cytoscape.png|Screenshot Network]]) | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|Cytoscape||Released||Visualization of gene regulatory network created in Reverse Engineering using [http://www.cytoscape.org/ Cytoscape 1.0]. ([[media:T_ARACNE_result1.png|Screenshot]]) | ||
|- | |- | ||
| − | |||
|- | |- | ||
| + | |width="150"|MINDy||Released||The Modulator Inference by Network Dynamics algorithm extends ARACNe to include detecting the influence of modulators of transcription factor activity. | ||
|- | |- | ||
|- | |- | ||
| − | | | + | |width="150"|NetBoost||Development||NetBoost is a network characterization algorithm. |
|- | |- | ||
|} | |} | ||
| − | |||
| − | {|style="border: 1px solid lightGray" | + | ==Normalization== |
| − | !Plugin||Description|| | + | |
| + | {|class = "wikitable" style="border: 1px solid lightGray" | ||
| + | !Plugin||Status||Description | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|Array-Based Centering||Released||Subtraction of the mean or median measurement of a microarray from every measurement in that microarray. | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|Housekeeping Normalizer||Released|| Normalization of all measurements in a microarray through division by the average expression value of a (user defined) set of housekeeping genes. | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|Log2 Normalizer||Released||Applies a log2 transformation to all measurements in a microarray. | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|Marker-Based Centering||Released||Subtraction of the mean or median measurement of a marker profile from every measurement in the profile. | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|Mean-Variance Normalizer||Released||Transformation of expression measurements to standard units: for every marker, the mean measurement of the marker profile (across all microarrays in an experiment) is subtracted from each measurement in the profile and the resulting value is divided by the standard deviation of the profile. | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|Missing Value Normalizer||Released||Replacement of missing values with consensus values. | ||
|- | |- | ||
| − | |||
|- | |- | ||
| + | |width="150"|Quantile Normalizer||Released|| Expression measurements in each microarray are adjusted so that the distribution of values is the same across all microarrays in an experiment. | ||
|- | |- | ||
| − | |||
|- | |- | ||
| + | |width="150"|Threshold Normalizer||Released||Adjustment of values that fall outside a user-specified threshold. | ||
|- | |- | ||
| − | |||
|- | |- | ||
| + | |} | ||
| + | |||
| + | |||
| + | == Protein Structure Analysis == | ||
| − | | | + | {|class = "wikitable" style="border: 1px solid lightGray" |
| − | = | + | !Plugin||Status||Description |
| − | + | |- | |
| − | !Plugin||Description|| | + | |- |
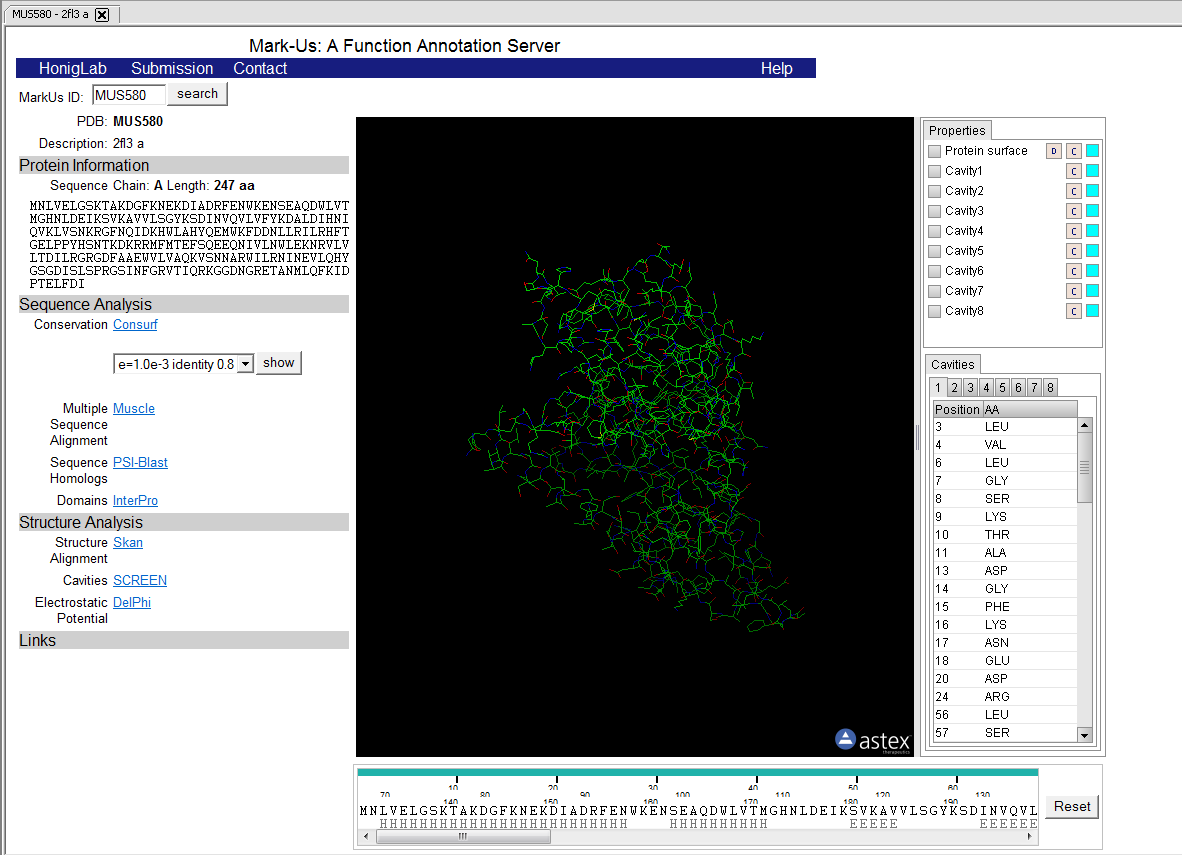
| + | |width="150"|MarkUs||Released||Assesses the biochemical function for a given protein structure. ([[media:T_MarkUs_Web_result.png|Screenshot]]) | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|Pudge||Released||Computational protein structure prediction using sequence homology. It integrates tools used at different stages of the structural prediction process. ([[media:T_Pudge_Parameters.png|Screenshot Parameters]], [[media:T_Pudge_Alignment_example.png|Screenshot Result]]) | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|SkyBase||Released||Database of protein structure models produced by SkyLine based on structures solved by the NESG structural genomics consortium. | ||
| + | |- | ||
|- | |- | ||
| + | |width="150"|SkyLine||Released||Automated high-throughput pipeline for reverse homology-based comparative protein structure modeling based on the input template structure. | ||
|- | |- | ||
| − | |||
| − | |||
|- | |- | ||
|} | |} | ||
| − | == | + | |
| − | {|style="border: 1px solid lightGray" | + | == Sequence Analysis & Visualization == |
| − | !Plugin||Description|| | + | |
| + | {|class = "wikitable" style="border: 1px solid lightGray" | ||
| + | !Plugin||Status||Description | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|Alignment Results||Released||It parses and displays the results of sequence similarity searches which were run on the NCBI BLAST service. ([[media:T_SequenceAlignment_BLAST_results.png|Screenshot]]) | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|Pattern Discovery||Released|| Discovery of sequence motifs in sets of DNA and protein sequences. ([[media:T_PatternDiscovery_Params_Basic_histone_result_exact_seqs.png|Screenshot]]) | ||
| + | |- | ||
|- | |- | ||
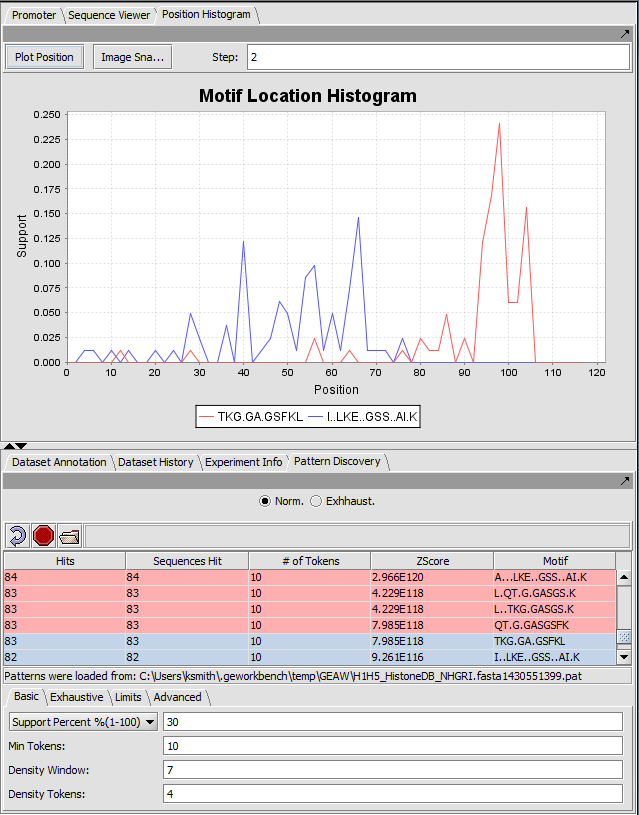
| + | |width="150"|Position Histogram ||Released|| Visualization of results from the Pattern Discovery plugin. Motif/pattern support is plotted against relative sequence position of the motif match. ([[media:T_PatternDiscovery_Histones_Result_exact_Position_Histogram.png|Screenshot]]) | ||
|- | |- | ||
| − | |||
| − | |||
|- | |- | ||
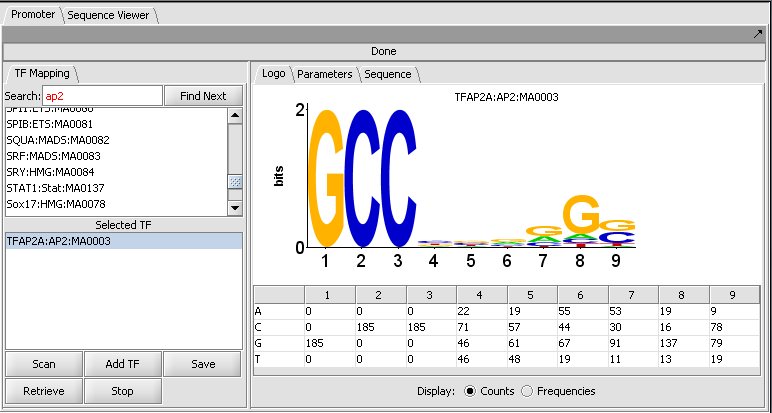
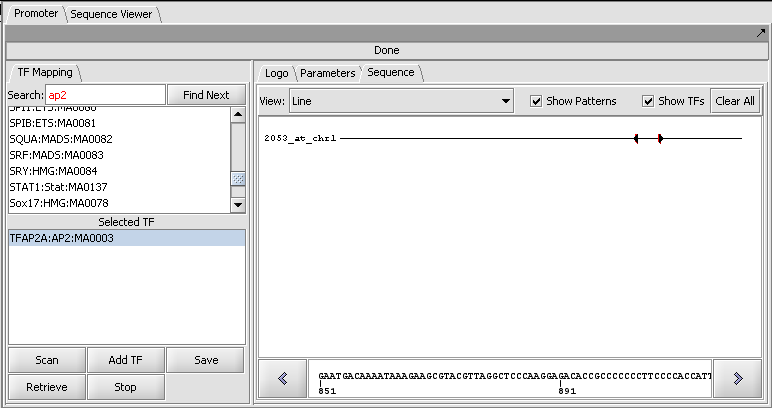
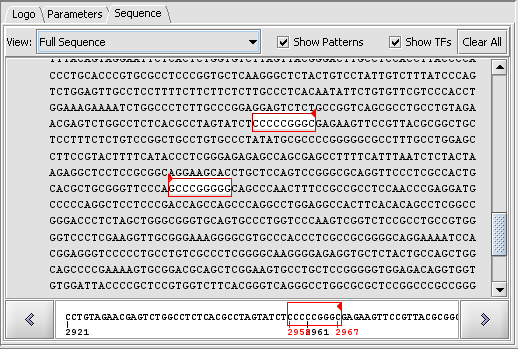
| + | |width="150"|Promoter Analysis||Released||Identification of putative transcription factor binding sites in DNA sequences. The analysis use the profiles in the [http://jaspar.cgb.ki.se/cgi-bin/jaspar_db.pl JASPAR Transcription Factor Binding Profile Database]. ([[media:T_Promoter_CDH2_AP2_2000updn_setup_logo.png|Screenshot Logo]], [[media:T_Promoter_CDH2_AP2_2000updn_scan.png|Screenshot Sequence 1]], [[media:T_Promoter_CDH2_AP2_2000updn_scan_fullseq.png|Screenshot Sequence 2]]) | ||
|- | |- | ||
| − | |||
| − | |||
|- | |- | ||
| − | + | |width="150"|Sequence Alignment||Released||Run jobs on the NCBI BLAST servers directly within geWorkbench. | |
|- | |- | ||
| − | |||
| − | |||
|- | |- | ||
| + | |width="150"|Sequence Panel ||Released|| Visualization of results from the Pattern Discovery plugin, displaying the motif match location over each sequence from the input data set. | ||
|- | |- | ||
| − | |||
|- | |- | ||
| + | |width="150"|Sequence Retriever||Released||Retrieve sequences for annotated markers from Santa Cruz (Nucleotides) and EBI (Proteins). ([[media:T_SequenceRetriever_AfterRetrieval.png|Screenshot]]) | ||
|- | |- | ||
| − | |||
|- | |- | ||
|} | |} | ||
| − | |||
| − | {|style="border: 1px solid lightGray" | + | |
| − | !Plugin||Description|| | + | ==Visualization== |
| + | |||
| + | {|class = "wikitable" style="border: 1px solid lightGray" | ||
| + | !Plugin||Status||Description | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|Analysis Panel||Released||Framework to support numerous, individually loadable analysis methods. | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|ANOVA Tabular Viewer||Released||Displays the results of ANOVA analysis of gene expression data in tabular format. ([[media:T_ANOVA_Tabular_Viewer.png|Screenshot]]) | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|CEL Image Viewer||Released||Visualization of data in Affymetrix CEL files. ([[media:T_CEL_viewer.png|Screenshot]]) | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|Color Mosaic||Released||Heat maps for microarray expression data, organized by phenotypic or gene groupings. ([[media:GeWB_Color_Mosaic_Viewer.png|Screenshot]]) | ||
| + | |- | ||
| + | |- | ||
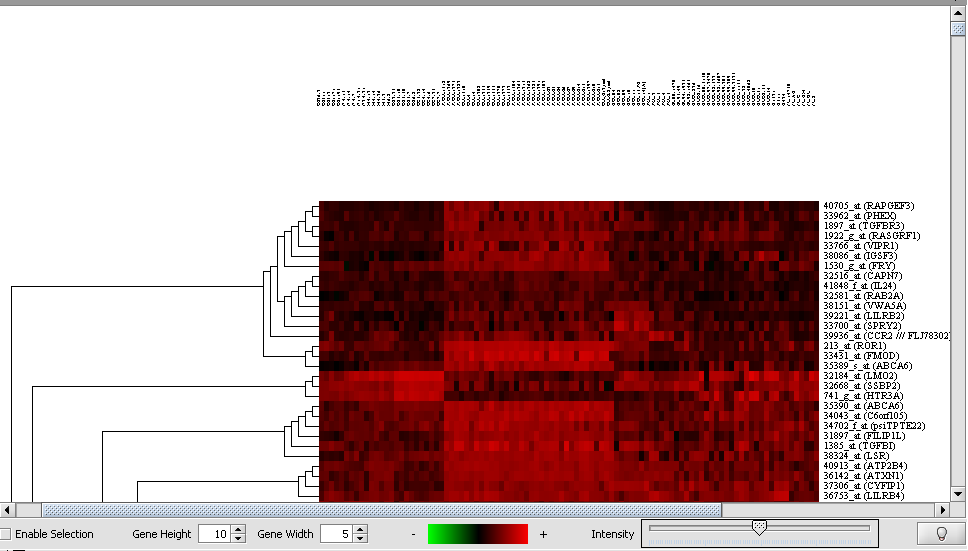
| + | |width="150"|Dendrogram||Released||Tree-structured diagrams reflecting the results of hierarchical clustering analysis. ([[media:T_HC_Dendrogram_display.png|Screenshot]]) | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|Evidence Integration Viewer||Development||Displays the results of the Evidence Integration analysis. | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|Expression Profiles||Released||Line graph of genes expression profiles across several arrays/ hybridizations. ([[media:GeWB_Expression_Profile_2markers.png|Screenshot]]) | ||
| + | |- | ||
| + | |- | ||
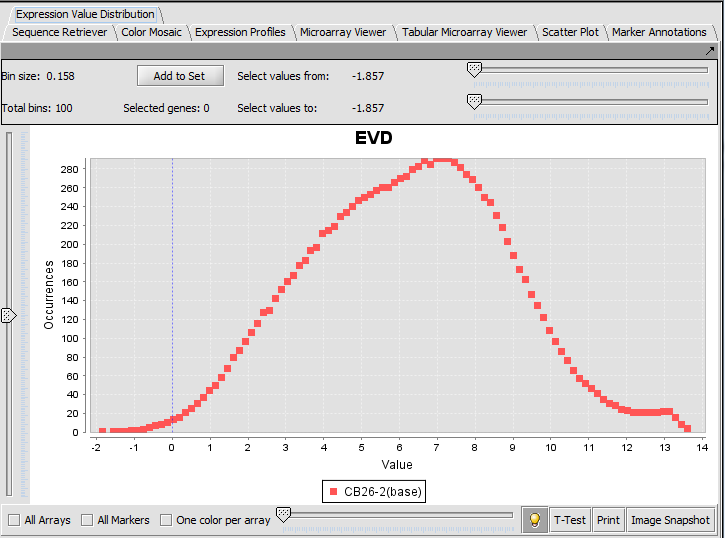
| + | |width="150"|Expression Value Distribution||Released||Distribution plot of marker expression values across one or more microarrays. ([[media:T_EVD.png|Screenshot]]) | ||
| + | |- | ||
|- | |- | ||
| + | |width="150"|GeneWays||Released||An essential component needed to display elements in Cytoscape and ARACNe. | ||
|- | |- | ||
| − | |||
|- | |- | ||
| + | |width="150"|GO Terms Viewer||Released||Displays the results of Gene Ontology Enrichment Analysis. ([[media:T_GO_Terms_TableBrowser_Gene_Detail.png|Screenshot]]) | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|Image Viewer||Released||Visualization of screenshots saved within geWorkbench (e.g. dendrograms). | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|Jmol||Released|| Visualization of 3D protein structures from PDB files. ([[media:T_JMOL_Viewer.png|Screenshot]]) | ||
| + | |- | ||
|- | |- | ||
| − | | | + | |width="150"|Mark-Us Browser||Released|| Displays the results of a Mark-Us analysis. ([[media:T_MarkUs_Web_result.png|Screenshot]]) |
| + | |- | ||
|- | |- | ||
| + | |width="150"|MatrixReduce||Released||Visualization of MatrixReduce calculations using logo, chromosomal and tabular displays. | ||
| + | |- | ||
|- | |- | ||
| − | | | + | |width="150"|MEDUSA Viewer||Development||Displays the results of a MEDUSA analysis. |
| + | |- | ||
|- | |- | ||
| + | |width="150"|Microarray Viewer||Released||Color-gradient representation of gene expression values. ([[media:GeWB_Microarray_Viewer.png|Screenshot]]) | ||
| + | |- | ||
|- | |- | ||
| − | | | + | |width="150"|MINDy Viewer||Released||The results of a MINDy calculation are presented in several different tabular displays and a heat map. |
| + | |- | ||
|- | |- | ||
| + | |width="150"|MRA Viewer||Released||Displays the results of the MRA in tablular and graphical form. ([[media:MRA_viewer_full.png|Screenshot]]) | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|NetBoost Viewer||Development||Displays a Boosting Iteration Graph, Confusion Matrix and Score Table from NetBoost Analysis. | ||
| + | |- | ||
|- | |- | ||
| − | | | + | |width="150"|Normalization Panel||Released||Framework to support numerous, individually loadable normalization components. |
| + | |- | ||
| + | |- | ||
| + | |width="150"|PCA Viewer||Released||Displays PCA results. | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|Pudge Browser||Released||Visualization of Pudge results. ([[media:T_Pudge_Parameters.png|Screenshot Parameters]], [[media:T_Pudge_Alignment_example.png|Screenshot Result]]) | ||
| + | |- | ||
| + | |- | ||
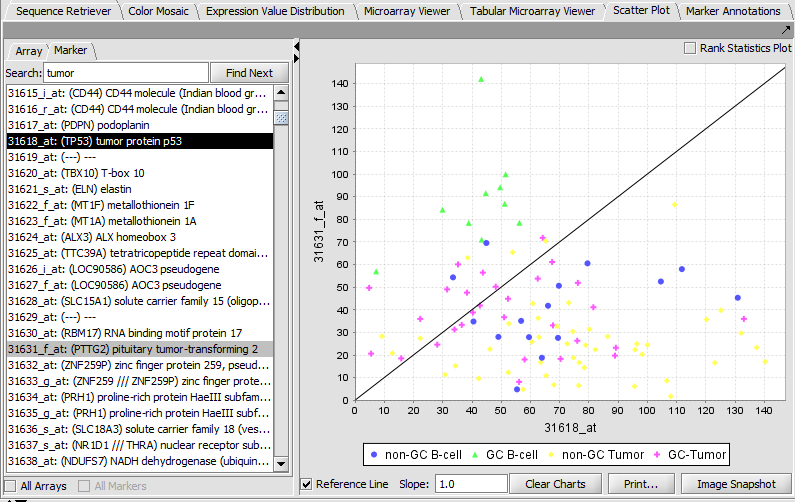
| + | |width="150"|Scatter Plot||Released||Pairwise (array vs. array and marker vs. marker) comparison and plotting of expression values. ([[media:GeWB_Scatter_Plot_array_vs_array.png|Screenshot Array]], [[media:GeWB_Scatter_Plot_marker_vs_marker.png|Screenshot Marker]]) | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|SkyBase Viewer||Released||Displays the results from the SkyBase search. | ||
| + | |- | ||
|- | |- | ||
| + | |width="150"|SkyLine Output All||Released||Displays all models from the Skyline modeling. | ||
| + | |- | ||
|- | |- | ||
| − | | | + | |width="150"|SkyLine Output Each||Released||Displays each model from the Skyline modeling. |
| + | |- | ||
| + | |- | ||
| + | |width="150"|SkyLine Contour||Development||A 2D dominance-based visualization of query results. | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|SOM Clusters Viewer||Released||Visualization of gene clusters produced by the self-organizing maps analysis. ([[media:T_SOM_result.png|Screenshot]]) | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"|SVM Viewer||Released||Visualizes results obtained from classifying samples based on SVMs generated using the Gene Pattern v3 SVM service. | ||
| + | |- | ||
| + | |- | ||
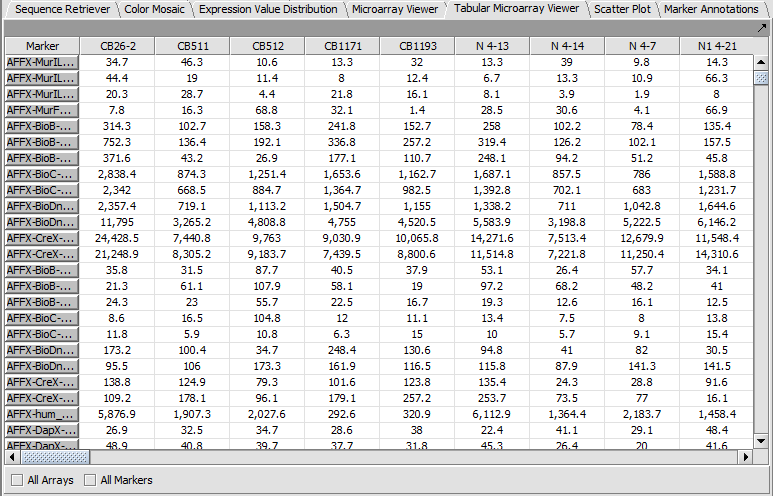
| + | |width="150"|Tabular Microarray Viewer||Released||Spreadsheet view of all expression measurement in an experiment, one row per individual marker/probe and one column per microarray. ([[media:GeWB_Tabular_Microarray_Viewer.png|Screenshot]]) | ||
| + | |- | ||
| + | |- | ||
| + | |width="150"| Volcano Plot||Released|| Visualize fold-change vs significance (P-value) for t-test results. ([[media:T_t-test_volcano_BCELL_webm_qldm.png|Screenshot]]) | ||
| + | |- | ||
|- | |- | ||
|} | |} | ||
Latest revision as of 10:17, 16 July 2013
The geWorkbench platform employs a component repository infrastructure to manage a large collection of pluggable components that can be used to customize the application's graphical user interface. This (ever growing) list of plug-in components covers a wide range of fucntionality for a number of different genomic data modalities.
The Status of the pluggable components below is defined as:
| Status | Comment |
|---|---|
| (a) Released | This plugin is part of the latest geWorkbench version. |
| (b) Development | This plugin is currently actively being developed. |
Contents
Analysis
| Plugin | Status | Description |
|---|---|---|
| ANOVA | Released | Analysis of Variance - detection of significant differences in expression between more than two groups. (Screenshot) |
| Evidence Integration | Development | A sequence and structure-based approach for functional annotation and protein-protein interaction analysis. |
| GSEA | Released | The Gene Set Enrichment Analysis determines whether an a priori defined set of genes shows statistically significant differences between two phenotypes. |
| Hierarchical Clustering | Released | Clustering of markers and microarrays into hierarchical binary trees. The resulting structures can be visualized in the Dendrogram plugin. (Screenshot) |
| KNN | Released | k-Nearest Neighbors analysis (a GenePattern component). |
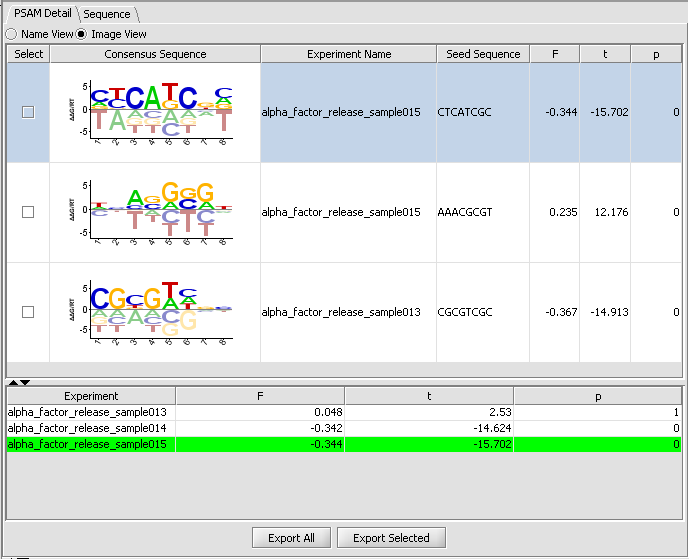
| MatrixReduce | Released | Transcription Factor binding motifs. (Screenshot) |
| MEDUSA | Development | The Motif Element Detection Using Sequence Agglomeration is an integrative method for learning motif models of transcription factor binding sites by incorporating promoter sequence and gene expression data (Leslie Lab, MSKCC). |
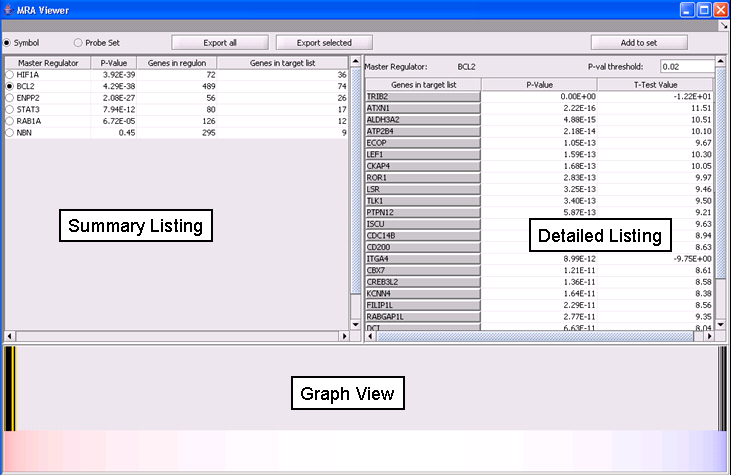
| MRA | Released | Master Regulator Analysis combines regulatory information from interaction networks with differential expression analysis. (Screenshot) |
| PCA | Released | Principal Component Analysis (a GenePattern component). |
| SOM | Released | Clustering of markers using Self Organizing Maps. The resulting clusters can be visualized in the SOM Clusters Viewer plugin. (Screenshot) |
| SVM 3.0 | Released | The Support Vector Machine is a supervised classification method that computes a maximal separating hyperplane between the expression vectors of different classes or phenotypes (a GenePattern component). |
| T-Test | Released | Identification of markers with statistically significant differential expression between sets of microarrays. (Screenshot Plot, Screenshot Mosaic) |
| Weighted Voting | Released | Weighted Voting Analysis (a GenePattern component). |
Annotation
| Plugin | Status | Description |
|---|---|---|
| caScript | Development | An Editor. |
| Dataset History | Released | Log of data transformations induced by data-modifying operations. |
| Experiment Information | Released | Microarray machine parameters used in an experiment run. If available, high-level experiment information (e.g., purpose of of experiment) are also displayed. |
| Gene Ontology Enrichment | Released | Enrichment analysis of selected groups of genes against Gene Ontology (http://www.geneontology.org) annotations. (Screenshot) |
| Marker Annotations | Released | Retrieval of gene and pathway information for markers on a microarray (caBIO Pathways/Cancer Gene Index); it includes visualization of BioCarta pathway diagrams. (Screenshot Table, Screenshot BioCarta, Screenshot CGI) |
Data Filtering
| Plugin | Status | Description |
|---|---|---|
| Affy Detection Call Filter | Released | Filtering of measurements based on the value of their "detection call" attribute (Affymetrix data only) . |
| Deviation Filter | Released | Filtering of markers with low dynamic range. |
| Expression Threshold Filter | Released | Elimination of measurements that fall outside a range of explression values. |
| 2-channel Threshold Filter | Released | Same as "Expression Threshold" filter but different threshold ranges can be specified for each channel (GenePix data only). |
| Genepix Flag Filter | Released | Filtering of measurements based on the value of their "Flags" attribute (GenePix data only). |
| Missing Value Filter | Released | Discards all markers that have missing measurements in more than a user specified number N of microarrays. |
Data Management
| Plugin | Status | Description |
|---|---|---|
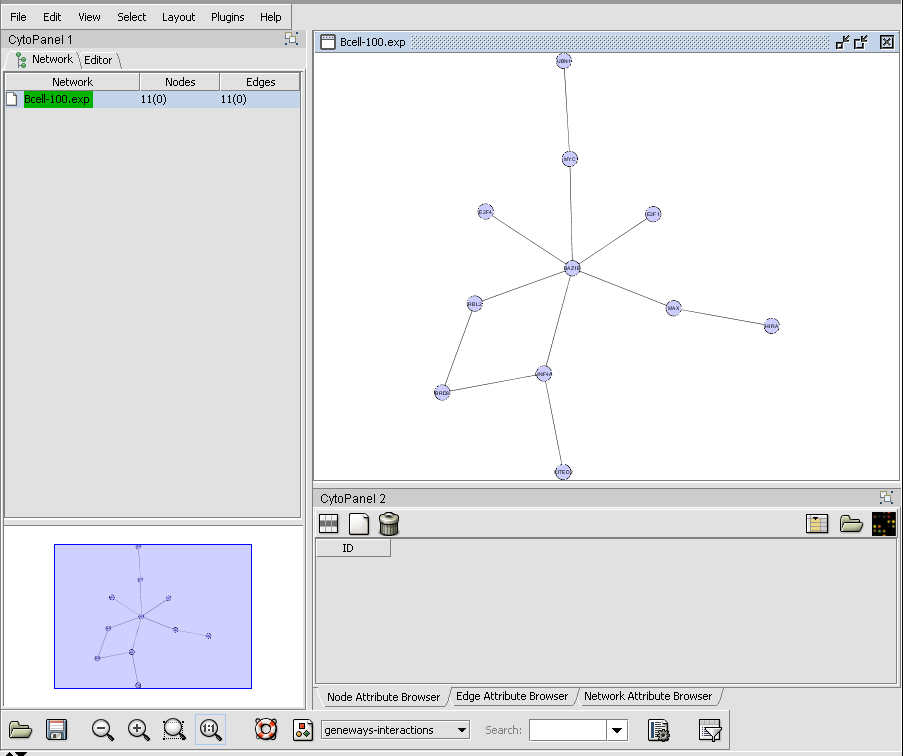
| Arrays/Phenotypes | Released | Definition of data views consisting of microarray subgroups. The views control the amount of data displayed. (Screenshot) |
| caArray | Released | Search and download of gene expression data from instances of caArray (NCI microarray database product). (Screenshot) |
| Markers | Released | Definition of data views consisting of marker subgroups. The views control the amount of data displayed. (Screenshot) |
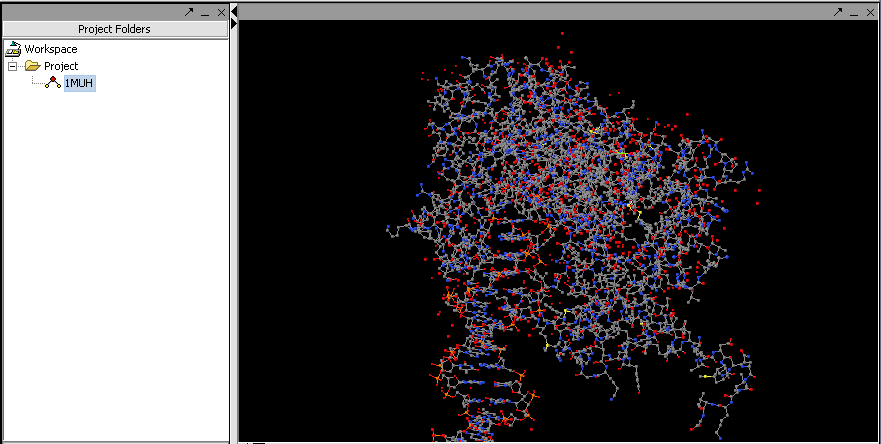
| Project Folders | Released | Manages projects and workspaces of the user. (Screenshot) |
File Import
| Plugin | Status | Description |
|---|---|---|
| Affymetrix CEL | Released | Loads Affymetrix probe CELl intensity files ("*.cel"). |
| Affymetrix File Matrix | Released | Loads Affymetrix EXPperiment files ("*.exp"). |
| Affymetrix MAS5/GCOS | Released | Loads output files from the GeneChip Operating Software formerly known as MAS5 Statistical algorithm (several different file extension). |
| FASTA Format | Released | Loads files that are in FASTA format ("*.fasta" and "*.txt"). |
| Genepix File Format | Released | Loads files in GenePix Result format ("*.gpr"). |
| PDB Structure Format | Released | Loads files in the Protein Data Base format ("*.pdb") |
| Tab-delimited (RMA Express Format) | Released | Loads tab-delimited files from the Robust Multichip Analysis ("*.txt") |
Menu Tools
| Plugin | Status | Description |
|---|---|---|
| CCM | Released | The Component Configuration Manager allows users to manage plugins dynamically at any given time in the application environment. (Screenshot) |
| genSpace | Released | It logs information about the analysis tools used in geWorkbench in order to enable collaboration support for the geWorkbench users. |
| Online Help | Released | geWorkbench Online Help uses the Java help 2.0 system to provide real-time help on component questions. |
| Preferences | Released | Allows users to predefine a few basic visual settings and choose a Text Editor. |
| Version Information | Released | Provides basic information about the currently installed user version of geWorkbench. |
| Welcome Screen | Released | Introduction to geWorkbench during the initial opening of the application. |
Network Generation
| Plugin | Status | Description |
|---|---|---|
| ARACNe | Released | The Algorithm for the Reconstruction of Accurate Cellular Networks analyses large amount of microarray data (typically 100-500 microarrays) to reverse engineer underlying gene regulatory networks. (Screenshot) |
| Cancer GEMS | Development | Interface to the NCI Cancer Genetic Markers of Susceptibility project. |
| CNKB | Released | The Cellular Networks Knowledge Base queries an in-house repository of locally generated B-cell interaction network data and information from external databases in order to build a network of interactions for selected genes. (Screenshot Throttle Graph, Screenshot Network) |
| Cytoscape | Released | Visualization of gene regulatory network created in Reverse Engineering using Cytoscape 1.0. (Screenshot) |
| MINDy | Released | The Modulator Inference by Network Dynamics algorithm extends ARACNe to include detecting the influence of modulators of transcription factor activity. |
| NetBoost | Development | NetBoost is a network characterization algorithm. |
Normalization
| Plugin | Status | Description |
|---|---|---|
| Array-Based Centering | Released | Subtraction of the mean or median measurement of a microarray from every measurement in that microarray. |
| Housekeeping Normalizer | Released | Normalization of all measurements in a microarray through division by the average expression value of a (user defined) set of housekeeping genes. |
| Log2 Normalizer | Released | Applies a log2 transformation to all measurements in a microarray. |
| Marker-Based Centering | Released | Subtraction of the mean or median measurement of a marker profile from every measurement in the profile. |
| Mean-Variance Normalizer | Released | Transformation of expression measurements to standard units: for every marker, the mean measurement of the marker profile (across all microarrays in an experiment) is subtracted from each measurement in the profile and the resulting value is divided by the standard deviation of the profile. |
| Missing Value Normalizer | Released | Replacement of missing values with consensus values. |
| Quantile Normalizer | Released | Expression measurements in each microarray are adjusted so that the distribution of values is the same across all microarrays in an experiment. |
| Threshold Normalizer | Released | Adjustment of values that fall outside a user-specified threshold. |
Protein Structure Analysis
| Plugin | Status | Description |
|---|---|---|
| MarkUs | Released | Assesses the biochemical function for a given protein structure. (Screenshot) |
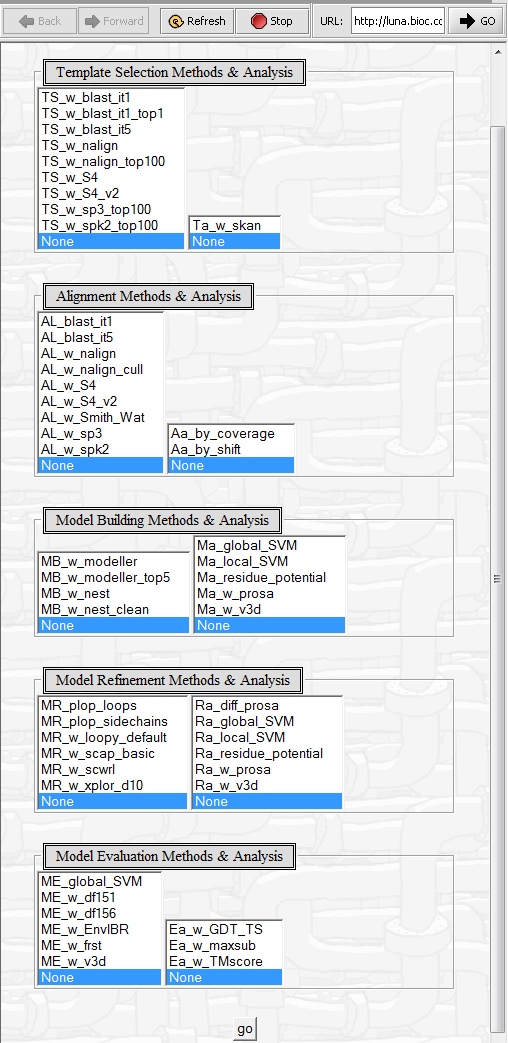
| Pudge | Released | Computational protein structure prediction using sequence homology. It integrates tools used at different stages of the structural prediction process. (Screenshot Parameters, Screenshot Result) |
| SkyBase | Released | Database of protein structure models produced by SkyLine based on structures solved by the NESG structural genomics consortium. |
| SkyLine | Released | Automated high-throughput pipeline for reverse homology-based comparative protein structure modeling based on the input template structure. |
Sequence Analysis & Visualization
| Plugin | Status | Description |
|---|---|---|
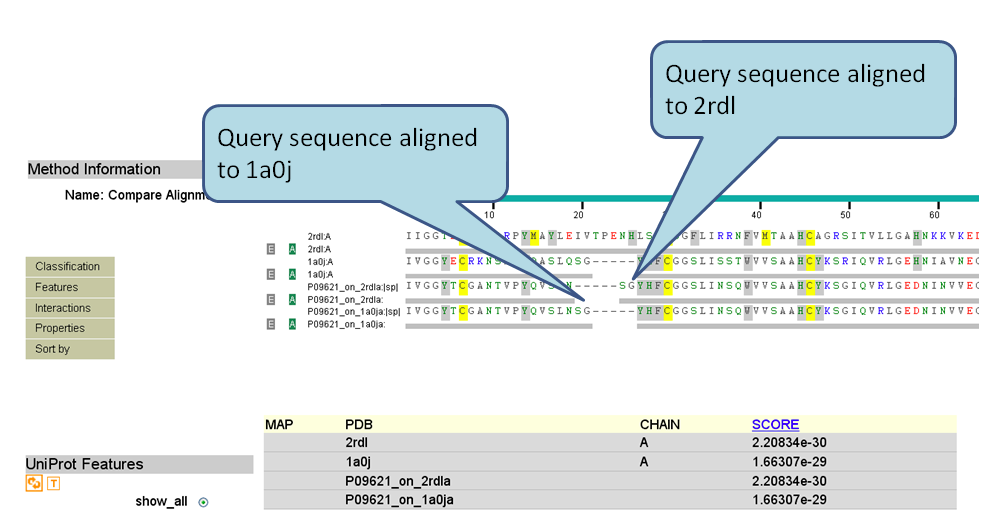
| Alignment Results | Released | It parses and displays the results of sequence similarity searches which were run on the NCBI BLAST service. (Screenshot) |
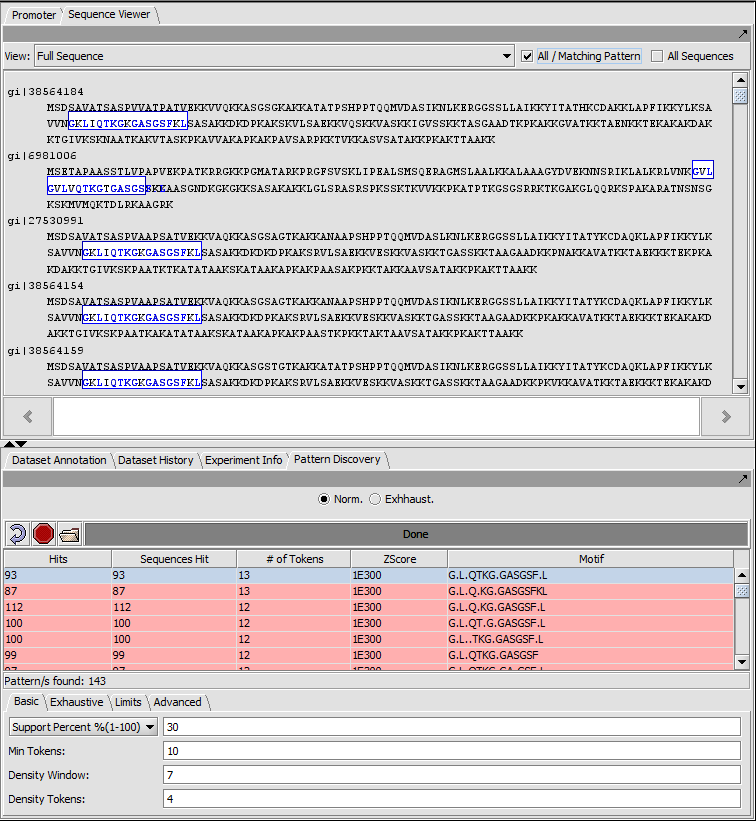
| Pattern Discovery | Released | Discovery of sequence motifs in sets of DNA and protein sequences. (Screenshot) |
| Position Histogram | Released | Visualization of results from the Pattern Discovery plugin. Motif/pattern support is plotted against relative sequence position of the motif match. (Screenshot) |
| Promoter Analysis | Released | Identification of putative transcription factor binding sites in DNA sequences. The analysis use the profiles in the JASPAR Transcription Factor Binding Profile Database. (Screenshot Logo, Screenshot Sequence 1, Screenshot Sequence 2) |
| Sequence Alignment | Released | Run jobs on the NCBI BLAST servers directly within geWorkbench. |
| Sequence Panel | Released | Visualization of results from the Pattern Discovery plugin, displaying the motif match location over each sequence from the input data set. |
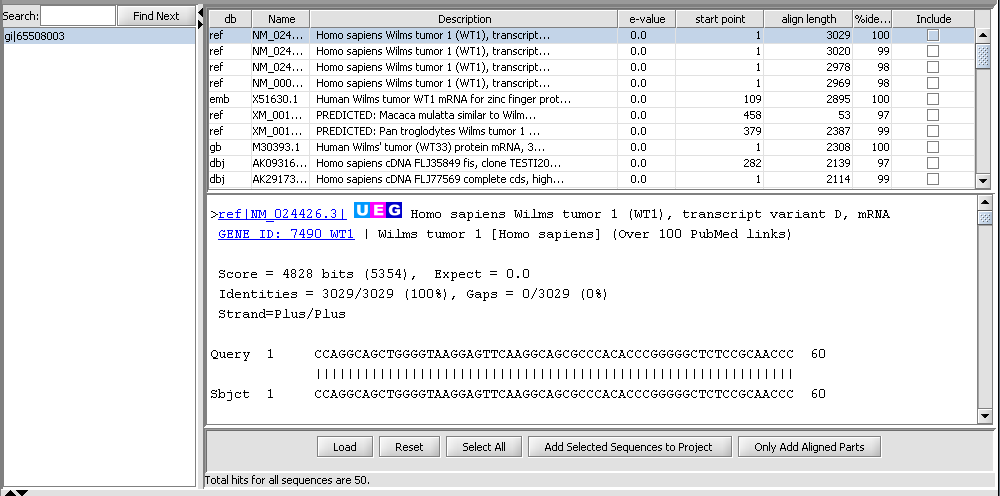
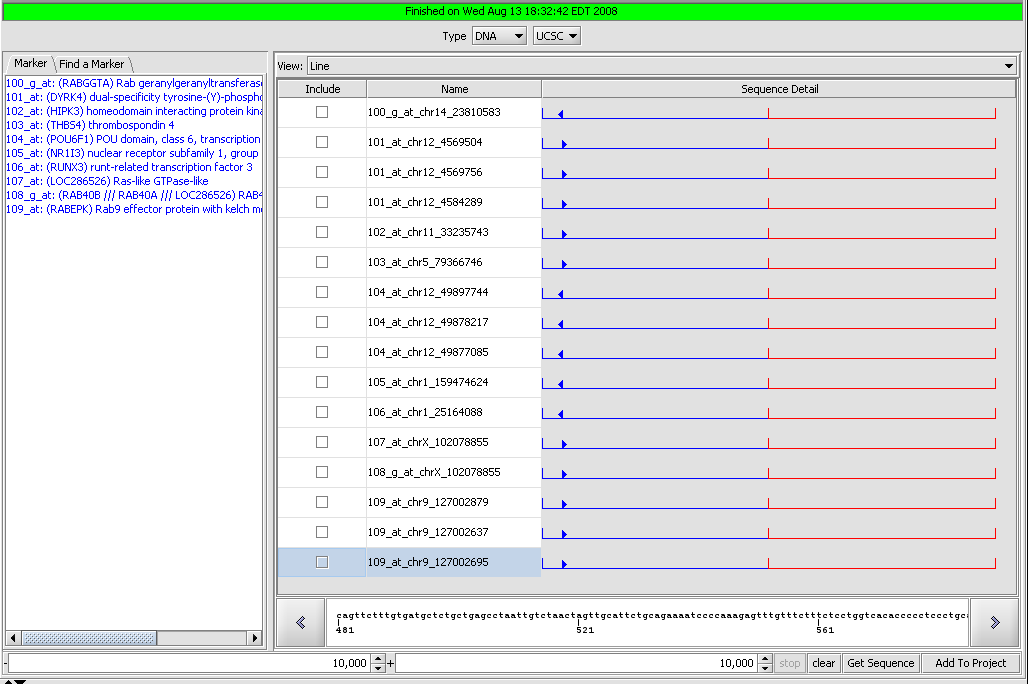
| Sequence Retriever | Released | Retrieve sequences for annotated markers from Santa Cruz (Nucleotides) and EBI (Proteins). (Screenshot) |
Visualization
| Plugin | Status | Description |
|---|---|---|
| Analysis Panel | Released | Framework to support numerous, individually loadable analysis methods. |
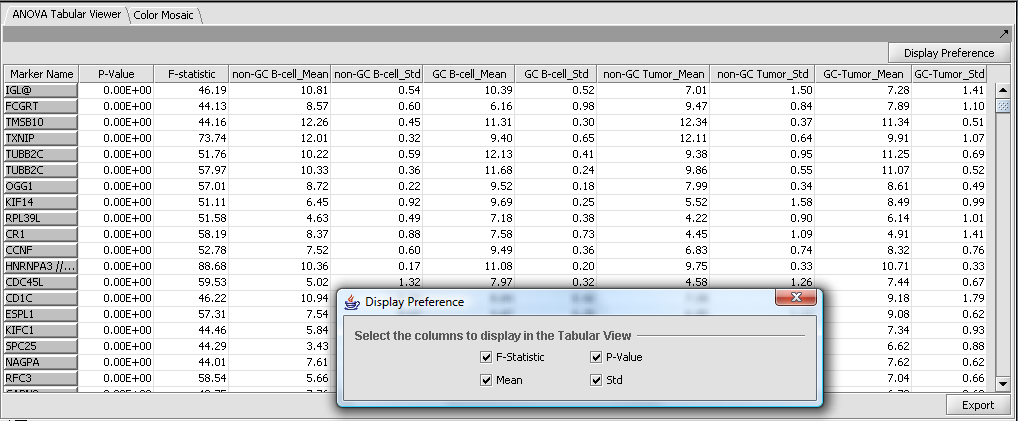
| ANOVA Tabular Viewer | Released | Displays the results of ANOVA analysis of gene expression data in tabular format. (Screenshot) |
| CEL Image Viewer | Released | Visualization of data in Affymetrix CEL files. (Screenshot) |
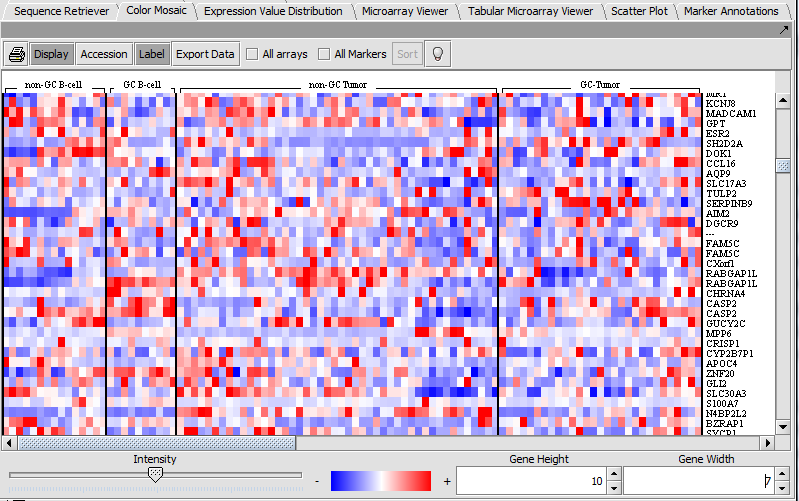
| Color Mosaic | Released | Heat maps for microarray expression data, organized by phenotypic or gene groupings. (Screenshot) |
| Dendrogram | Released | Tree-structured diagrams reflecting the results of hierarchical clustering analysis. (Screenshot) |
| Evidence Integration Viewer | Development | Displays the results of the Evidence Integration analysis. |
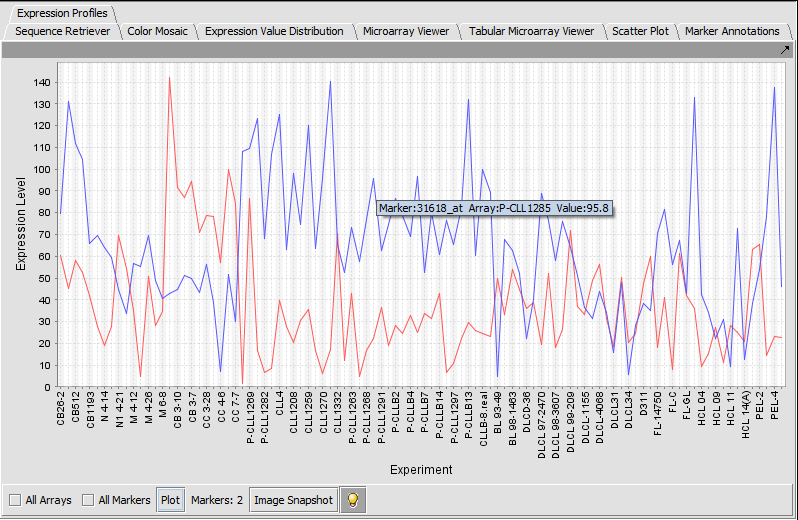
| Expression Profiles | Released | Line graph of genes expression profiles across several arrays/ hybridizations. (Screenshot) |
| Expression Value Distribution | Released | Distribution plot of marker expression values across one or more microarrays. (Screenshot) |
| GeneWays | Released | An essential component needed to display elements in Cytoscape and ARACNe. |
| GO Terms Viewer | Released | Displays the results of Gene Ontology Enrichment Analysis. (Screenshot) |
| Image Viewer | Released | Visualization of screenshots saved within geWorkbench (e.g. dendrograms). |
| Jmol | Released | Visualization of 3D protein structures from PDB files. (Screenshot) |
| Mark-Us Browser | Released | Displays the results of a Mark-Us analysis. (Screenshot) |
| MatrixReduce | Released | Visualization of MatrixReduce calculations using logo, chromosomal and tabular displays. |
| MEDUSA Viewer | Development | Displays the results of a MEDUSA analysis. |
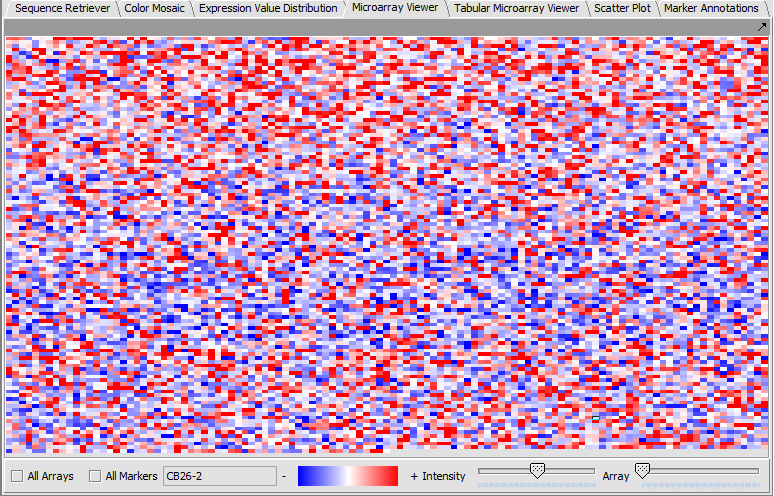
| Microarray Viewer | Released | Color-gradient representation of gene expression values. (Screenshot) |
| MINDy Viewer | Released | The results of a MINDy calculation are presented in several different tabular displays and a heat map. |
| MRA Viewer | Released | Displays the results of the MRA in tablular and graphical form. (Screenshot) |
| NetBoost Viewer | Development | Displays a Boosting Iteration Graph, Confusion Matrix and Score Table from NetBoost Analysis. |
| Normalization Panel | Released | Framework to support numerous, individually loadable normalization components. |
| PCA Viewer | Released | Displays PCA results. |
| Pudge Browser | Released | Visualization of Pudge results. (Screenshot Parameters, Screenshot Result) |
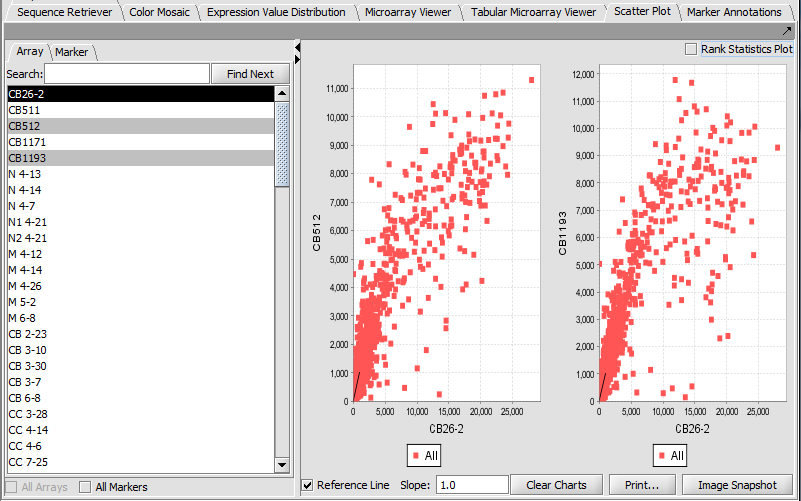
| Scatter Plot | Released | Pairwise (array vs. array and marker vs. marker) comparison and plotting of expression values. (Screenshot Array, Screenshot Marker) |
| SkyBase Viewer | Released | Displays the results from the SkyBase search. |
| SkyLine Output All | Released | Displays all models from the Skyline modeling. |
| SkyLine Output Each | Released | Displays each model from the Skyline modeling. |
| SkyLine Contour | Development | A 2D dominance-based visualization of query results. |
| SOM Clusters Viewer | Released | Visualization of gene clusters produced by the self-organizing maps analysis. (Screenshot) |
| SVM Viewer | Released | Visualizes results obtained from classifying samples based on SVMs generated using the Gene Pattern v3 SVM service. |
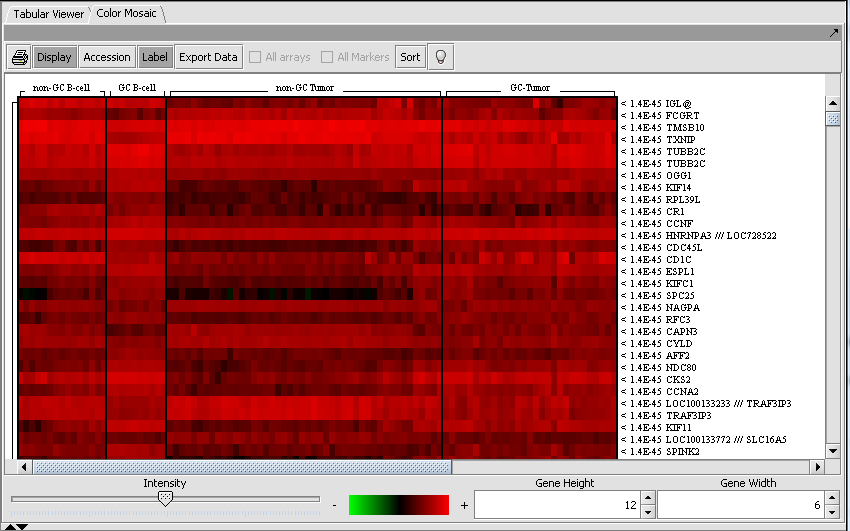
| Tabular Microarray Viewer | Released | Spreadsheet view of all expression measurement in an experiment, one row per individual marker/probe and one column per microarray. (Screenshot) |
| Volcano Plot | Released | Visualize fold-change vs significance (P-value) for t-test results. (Screenshot) |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}